TECMH: Transformer-Based Cross-Modal Hashing For Fine-Grained Image-Text Retrieval
Featured in:
Computers, Materials & Continua 2023
Authors:
Qiqi Li, Longfei Ma, Zheng Jiang, Mingyong Li and Bo Jin
Abstract
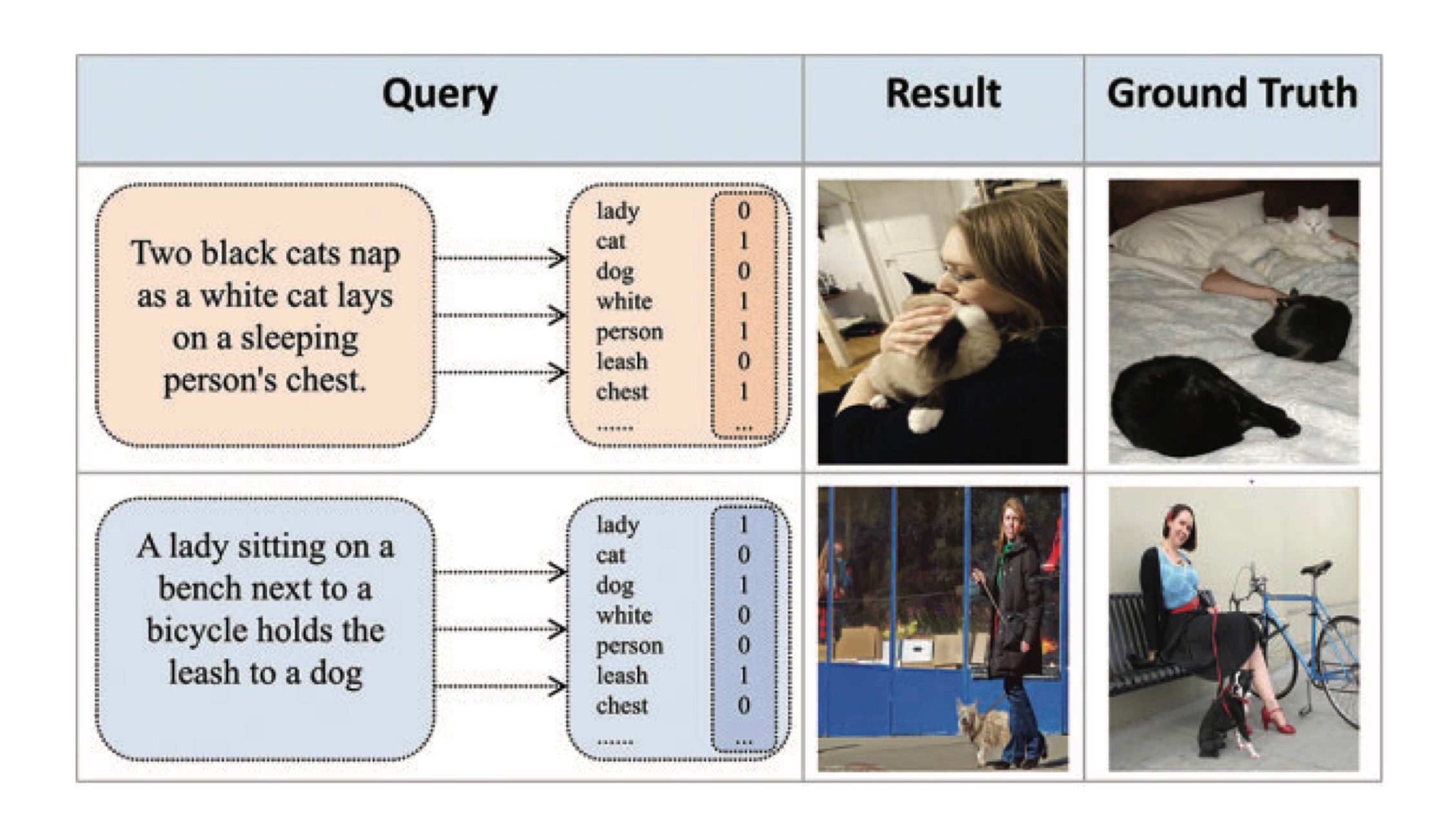
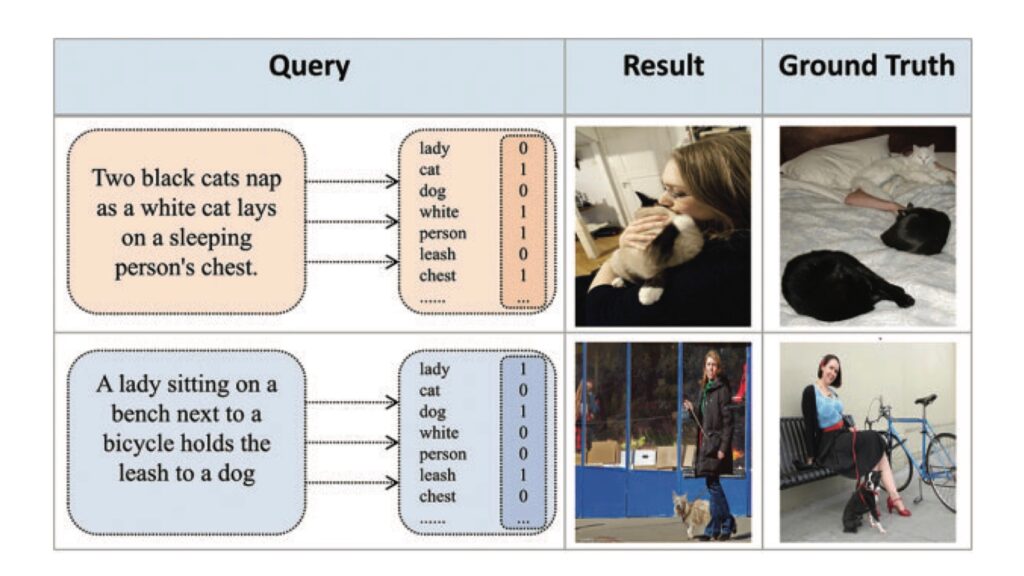
In recent years, cross-modal hash retrieval has become a popular research field because of its advantages of high efficiency and low storage. Cross-modal retrieval technology can be applied to search engines, cross-modal medical processing, etc. The existing main method is to use a multi-label matching paradigm to finish the retrieval tasks. However, such methods do not use fine-grained information in the multi-modal data, which may lead to sub-optimal results. To avoid cross-modal matching turning into label matching, this paper proposes an end-to-end fine-grained cross-modal hash retrieval method, which can focus more on the fine-grained semantic information of multi-modal data. First, the method refines the image features and no longer uses multiple labels to represent text features but uses BERT for processing. Second, this method uses the inference capabilities of the transformer encoder to generate global fine-grained features. Finally, in order to better judge the effect of the fine-grained model, this paper uses the datasets in the image text matching field instead of the traditional label-matching datasets. This article experiment on Microsoft COCO (MS-COCO) and Flickr30K datasets and compare it with the previous classical methods. The experimental results show that this method can obtain more advanced results in the cross-modal hash retrieval field.
Citation
Qiqi Li, Longfei Ma, Zheng Jiang, Mingyong Li and Bo Jin (2023). TECMH: Transformer-Based Cross-Modal Hashing For Fine-Grained Image-Text Retrieval. Computers, Materials & Continua, 75(2). DOI: 10.32604/cmc.2023.037463
FLOWING: Implicit Neural Flows for Structure-Preserving Morphing
Authors: Arthur Bizzi; Matias Grynberg; Vitor Matias; Daniel Perazzo; João Paulo Lima; Luiz Velho; Nuno Gonçalves; João Pereira; Guilherme Schardong; Tiago Novello
Featured in: 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
Adversarial Attack Challenge for Secure Face Recognition 2025
Authors: João Tremoço, Iurii Medvedev, Nuno Freitas, Andreia Costa, Diogo Nunes, Niklas Bunzel, Lukas Graner, Nicholas Göller, Lorenzo Pellegrini, Nicolò Di Domenico, Guido Borghi, Monson Verghese, Shruti Bhilare, Avik Hati, Miguel Lourenço, Nuno Gonçalves
Featured in: IEEE International Joint Conference on Biometrics (IJCB 2025)
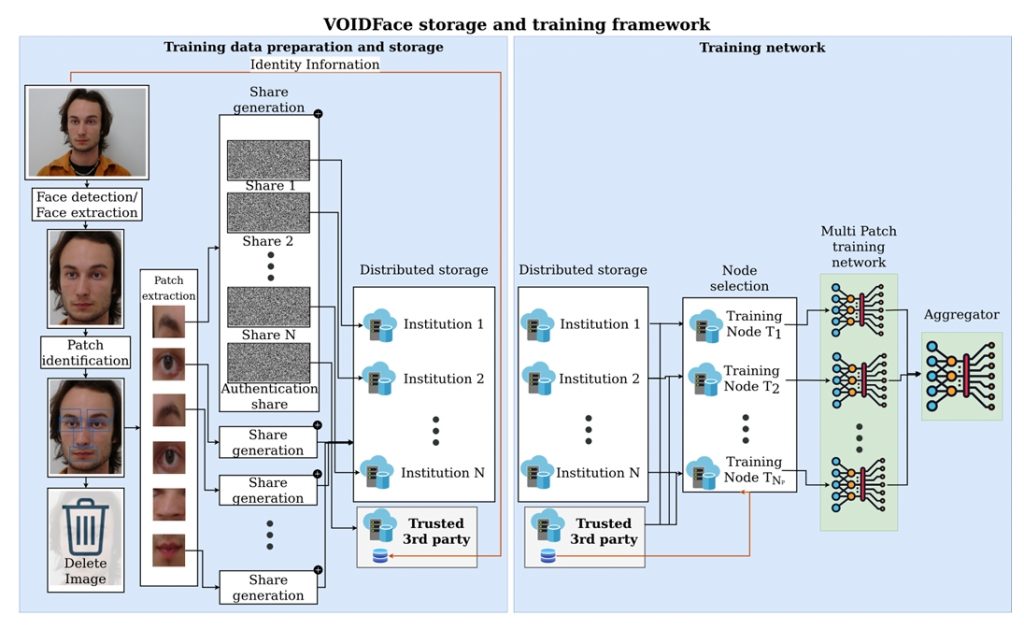
VOIDFace: A Privacy-Preserving Multi-Network Face Recognition With Enhanced Security