Web Page Classification using Text and Visual Features
Featured in:
MD Thesis
Authors:
João Costa
Abstract
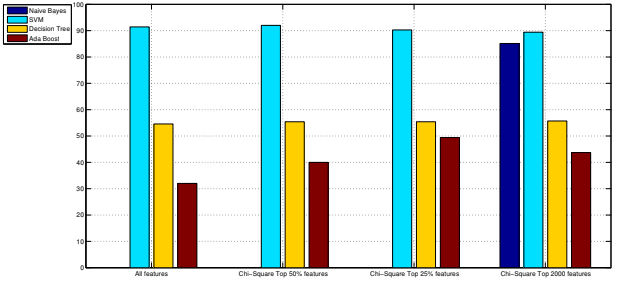
The world of Internet grows up every day. There are a large number of web pages actives at this moment and more are released every day. It is impossible to perform the web page classification manually. It was already developed several approaches in this area. Most of them only use the text information contained in the web pages, ignoring the visual content of them. This work shows that the visual content can improve the accuracies of the classifications that only use the text. It was extracted the text features of the web pages using the term frequency inverse document frequency method. As well, it was also extracted two different types of visual features: the low-level features and the local SIFT ones. Since the amount of the SIFT features is extremely high, it was created a dictionary using the “Bag-of-Words” method. After this extraction the features were merged, using all the types of combinations of them. It was also used the Chi-Square method that selects the best features of a vector. In the classification it was used four different classifiers. It was implemented a multi-label classification, for which we gave unknown web pages to the classifiers, so they could predict the main topic of the web page. It was also implemented a binary classification, for which we used only visual features to verify if a web page was a blog or non-blog. It was obtained good results that shows that adding the visual content to the text the accuracies improve. The best classification it was obtained using only four different categories, where was achieved 98% of accuracy. Later it was developed a web application, where the user can find out the main topic of a web page only inserting the web page URL. It can be accessed in ”http://scrat.isr.uc.pt/uniprojection /wpc.html”.
Citation
João Costa (2014), Web Page Classification using Text and Visual Features. MD thesis. University of Coimbra, 2014.
FLOWING: Implicit Neural Flows for Structure-Preserving Morphing
Authors: Arthur Bizzi; Matias Grynberg; Vitor Matias; Daniel Perazzo; João Paulo Lima; Luiz Velho; Nuno Gonçalves; João Pereira; Guilherme Schardong; Tiago Novello
Featured in: 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
Adversarial Attack Challenge for Secure Face Recognition 2025
Authors: João Tremoço, Iurii Medvedev, Nuno Freitas, Andreia Costa, Diogo Nunes, Niklas Bunzel, Lukas Graner, Nicholas Göller, Lorenzo Pellegrini, Nicolò Di Domenico, Guido Borghi, Monson Verghese, Shruti Bhilare, Avik Hati, Miguel Lourenço, Nuno Gonçalves
Featured in: IEEE International Joint Conference on Biometrics (IJCB 2025)
VOIDFace: A Privacy-Preserving Multi-Network Face Recognition With Enhanced Security