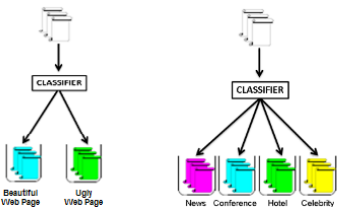
With the increase in the number of Internet users, the growing of websites is proportional, thereby web page classification has become a huge topic of research in the last few years. There is a constantly increasing requirement for automatic classification techniques with greater classification accuracy. To automatically classify and process web pages, the current systems use the textual content of those pages, which includes both the displayed content and the underlying HTML code. However, until now,
little work has been done on using the visual content of a web page to perform classification. On this account, in this thesis we focus on performing web page classification using their visual content. The web pages can present different and varied visual information depending on their specific topic. In this work I build a classification system to enable automatic analysis of a web page visual appearance as it appears to the user. First a descriptor is construct, by extracting different features from each page. The features used are the simple color and edge histogram, Gabor and texture features. Then two methods of feature selection, one based on the Chi-Square criterion, the other on the Principal Components Analysis are applied to that descriptor, to select the top attributes. Another approach involves using the Bag of Words (BoW) model to treat the SIFT local features extracted from each image as words, allowing to construct a dictionary. Then it is possible to describe new images by extracting the local features from them and matching them with features in the dictionary which are closest. Then we classify web pages based on their aesthetic value, their recency and type of website. The machine learning methods used in this work are the Na ̈ıve Bayes, Support Vector Machine, Decision Tree and AdaBoost. Different tests are performed to evaluate the performance of each classifier in each experiment. And by investigating our approach in detail, we are able to draw general conclusions and statements about whether or not the visual content should be ignored when performing web page classification. The main advantage of our approach is the good accuracy in each experiment.
Citation
António Videira (2013), Web Page Classification using Visual Features. MD thesis (in Portuguese). University of Coimbra, 2013.
Related Content
No tagged content to show
No tagged content to show
No tagged content to show
No tagged content to show
RECENT PUBLICATIONS
VOIDFace: A Privacy-Preserving Multi-Network Face Recognition With Enhanced Security